
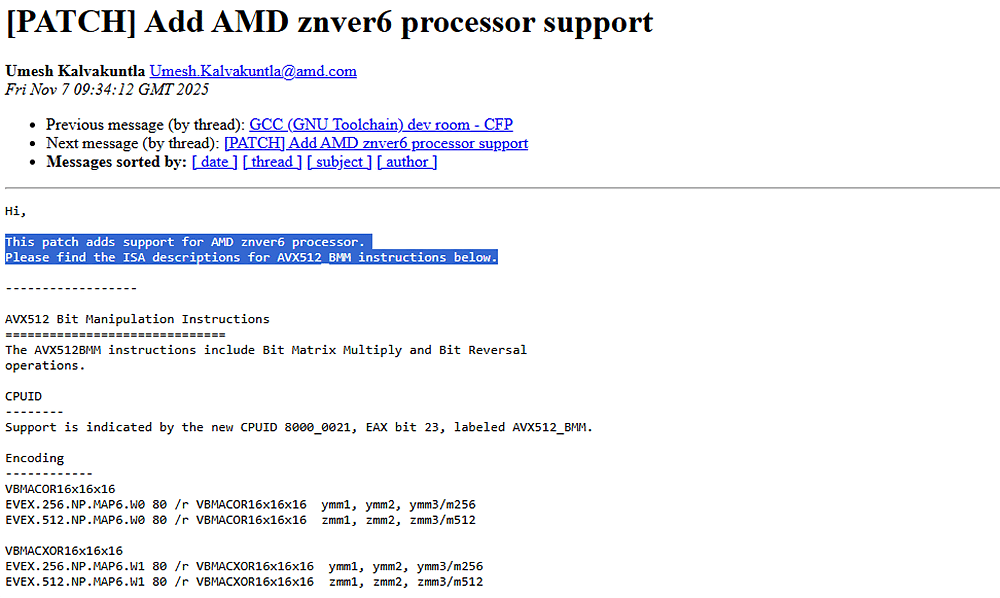
AMD ha dado un paso firme hacia el futuro de la inteligencia artificial con una actualización silenciosa, pero de gran relevancia técnica. Su nuevo aporte al repositorio GNU Binutils confirma que Zen 6 ya cuenta con soporte de software y traerá un conjunto de instrucciones diseñado para marcar la diferencia: AVX512_BMM. Esta extensión permite cálculos binarios y multiplicaciones matriciales que prometen acelerar la inferencia de IA de forma notable. Puede parecer un detalle técnico, pero en realidad, supone un cambio estratégico dentro del ecosistema x86.
El parche no es una simple formalidad. Estas actualizaciones suelen anticipar las capacidades reales del silicio antes de su llegada al mercado, y AMD ha incluido el identificador znver6, lo que permite a los desarrolladores compilar código optimizado para Zen 6 desde ya. Lo más llamativo es el nuevo AVX512_BMM (Bit Manipulation Matrix), una extensión que amplía AVX-512 con operaciones sobre matrices de 16×16. Entre ellas se incluyen VBMACOR16x16x16, VBMACXOR16x16x16 y VBITREV, instrucciones clave para cálculos lógicos, cifrado y tareas de inferencia neuronal de baja precisión. En otras palabras, AMD quiere competir directamente con Intel y NVIDIA en el terreno de la IA.
Mientras Zen 5 completó la transición hacia el cálculo vectorizado con soporte para AVX-512, VNNI y FP16, Zen 6 da un paso más allá. Su foco está en la computación binaria pura, un tipo de procesamiento donde las operaciones lógicas reemplazan los números de coma flotante. Este enfoque permite ejecutar redes neuronales con precisión INT4 o binaria, reduciendo el consumo energético y mejorando el rendimiento por vatio. Así, AMD busca ponerse al nivel de las arquitecturas híbridas de Intel y las GPU dedicadas de NVIDIA.
El documento técnico revela además un nuevo bit (el 23 del CPUID 0x80000021), que servirá para identificar las futuras CPU Venice, Medusa, Gator y Olympic. Este indicador confirma su compatibilidad con AVX512_BMM, pero también marca un cambio profundo: los procesadores Zen 6 podrán ejecutar parte de las inferencias directamente desde la CPU, sin depender de aceleradores externos. Dicho de otro modo, AMD está integrando dentro de su arquitectura general capacidades que antes estaban reservadas a las GPU o las NPU.
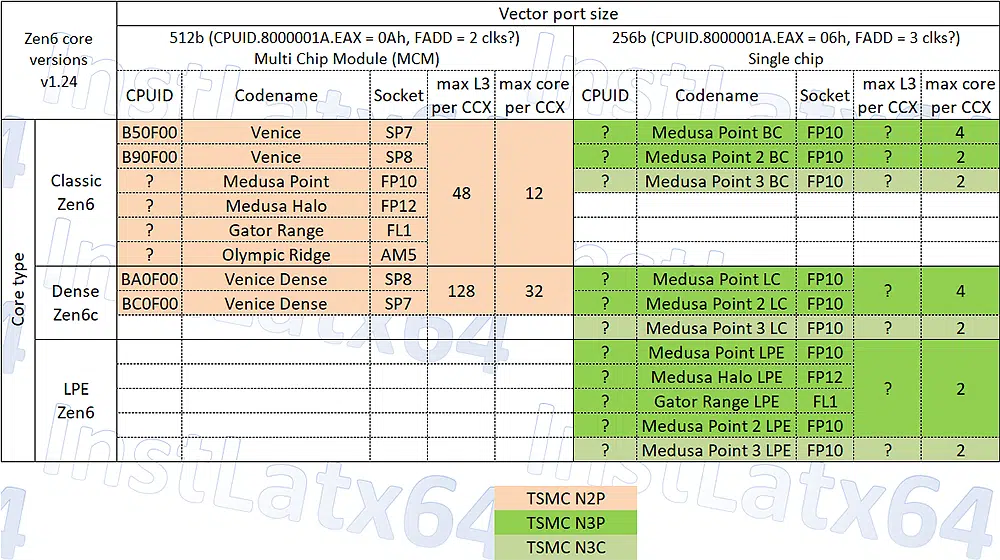
El movimiento es la respuesta directa a Intel AMX, aunque con una filosofía distinta. En lugar de crear bloques matriciales específicos, AMD reutiliza los registros vectoriales AVX512 existentes para lograr capacidades de inferencia más eficientes. Si Zen 5 consolidó el dominio del cálculo vectorial, Zen 6 podría convertirse en el punto de inflexión que marque el inicio del procesamiento binario dentro del mundo x86.
La batalla que se aproxima será apasionante. Los EPYC Venice competirán contra los Xeon Diamond Rapids, y las tecnologías AVX512_BMM y AMX medirán fuerzas en el terreno de la IA. Lo que hoy parece un cambio discreto en un repositorio de código podría ser el inicio de una nueva era para la computación de propósito general.
AMD no quiere seguir la tendencia: quiere redibujar el mapa del rendimiento inteligente.





